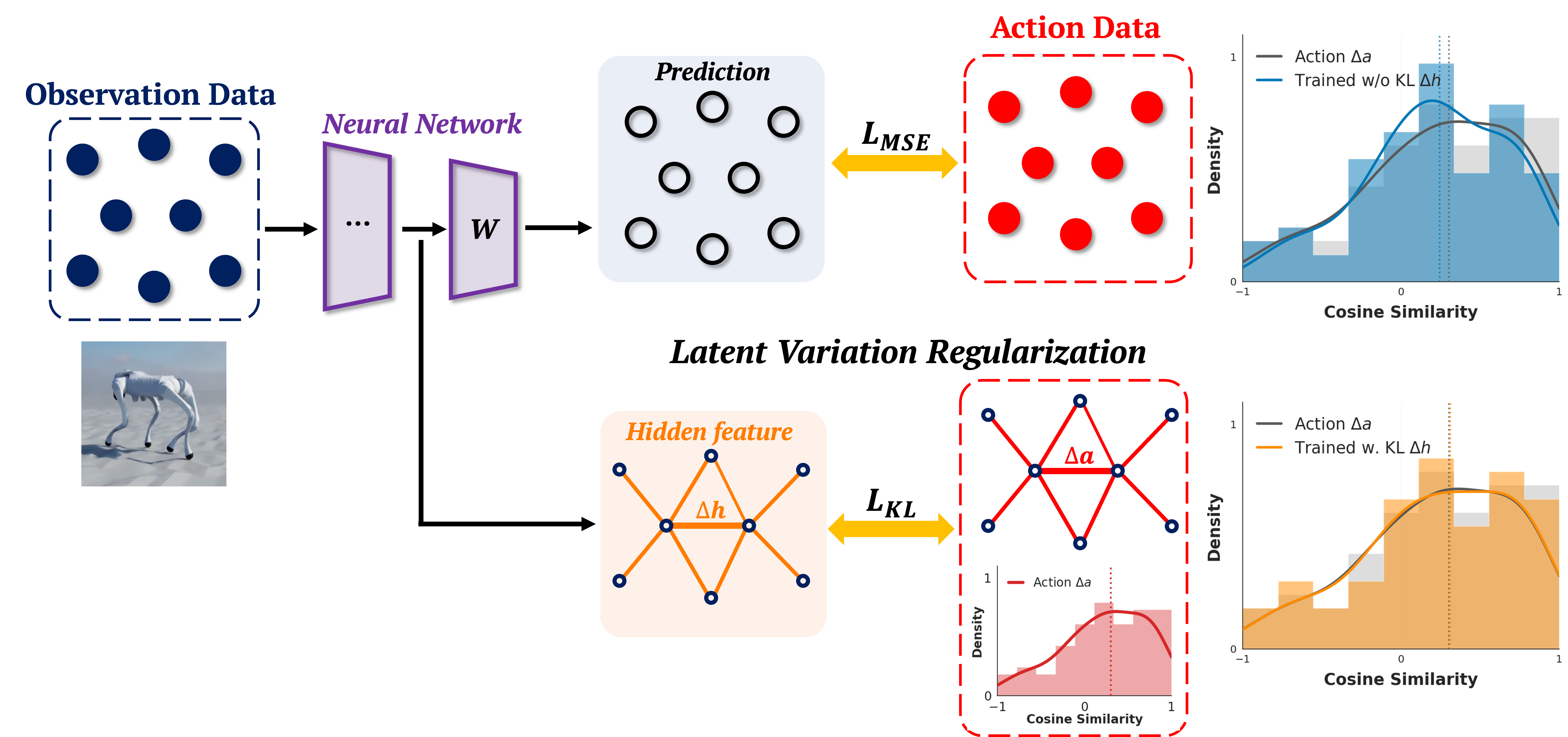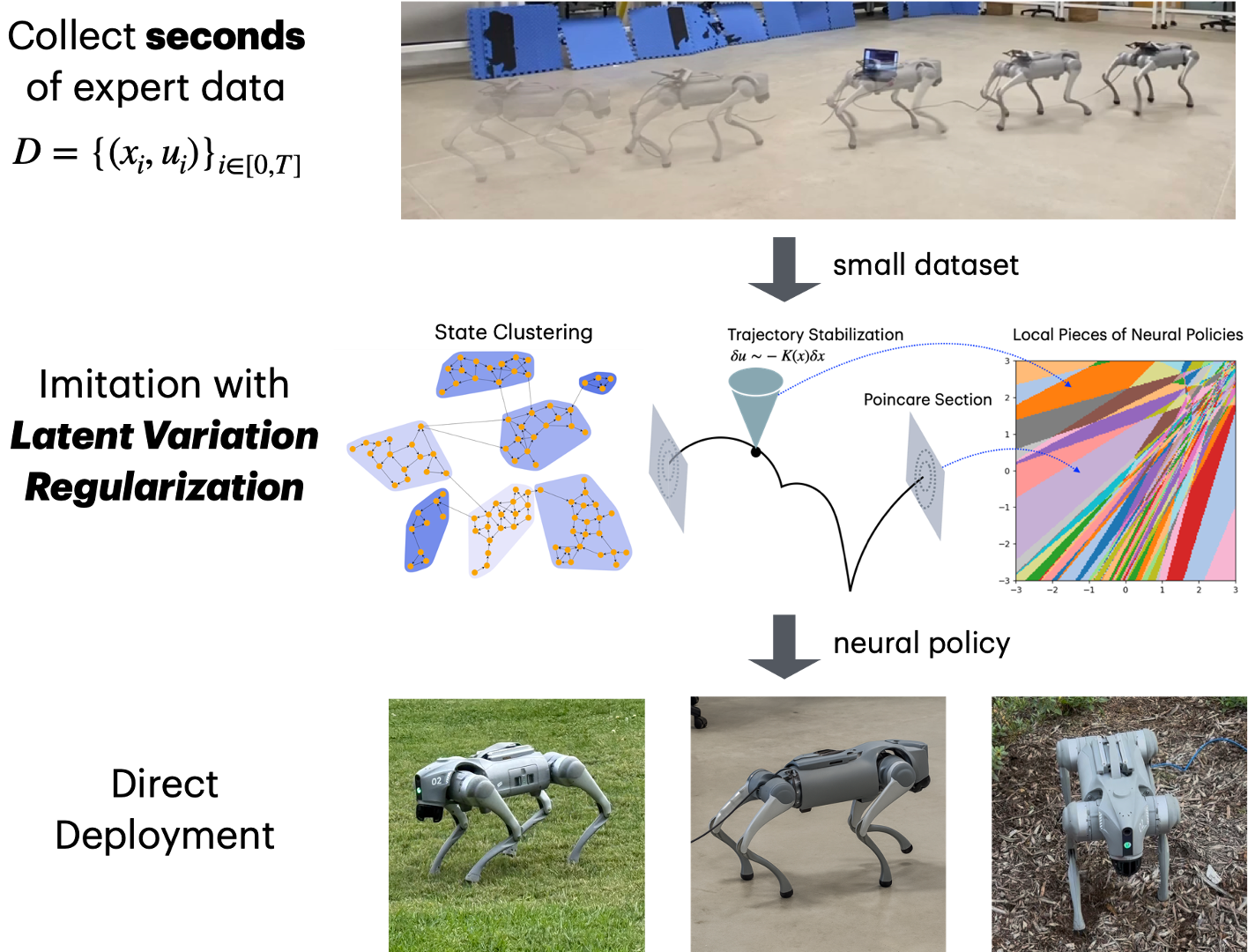
Abstract
Quadruped locomotion provides a natural setting for understanding when model-free learning can outperform model-based control design, by exploiting data patterns to bypass the difficulty of optimizing over discrete contacts and mode changes. We give a principled analysis of why imitation learning with quadrupeds can be effective in a small data regime, based on the structure of limit cycles, Poincaré return maps, and local numerical properties of neural networks. The understanding motivates a new imitation learning method Latent Variation Regularization (LVR) that regularizes the alignment of distributions in a latent representation space with the output action variations. Hardware experiments confirm that a few seconds of demonstration is sufficient to train locomotion policies from scratch entirely offline with reasonable robustness.